异常检测是异常值分析中的一项统计任务,但是如果我们开发一个机器学习模型来自动化地进行异常检测,可以节省很多时间。异常检测有很多用例,包括信用卡欺诈检测、故障机器检测、基于异常特征的硬件系统检测、基于医疗记录的疾病检测都是很好的例子,除此之外也还有很多的用例。在这里,我将使用Python从头开始实现异常检测算法。
公式和过程与我之前解释过的其他机器学习算法相比,我们使用的异常检测算法要简单得多。该算法使用均值和方差来计算每个训练数据的概率。如果一个训练实例的概率很高,则是正常的;如果某个训练实例的概率很低,那就可以是一个异常样本。对于不同的训练集,高概率和低概率的定义是不同的,这个我们以后再讨论。接下来我们来看一下异常检测的工作过程。使用以下公式计算平均值:
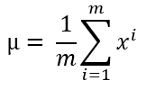
这里m是数据集的长度或训练数据的数量,而是一个单独的训练例子。如果你有多个训练特征,大多数情况下都需要计算每个特征的平均值。使用以下公式计算方差:

这里,mu是上一步计算的平均值。现在,用这个概率公式来计算每个训练例子的概率。
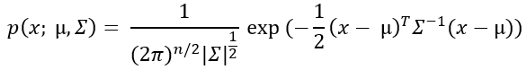
不要被这个公式中的求和符号弄糊涂了!这实际上是Sigma方差。稍后我们实现该算法时,就会理解它了。现在我们需要找到概率的临界值。正如我前面提到的,如果一个训练例子的概率很低,那这就是一个异常样本。多大是低概率呢这没有统一的标准,我们需要为我们的训练数据集找出这个阈值。我们从步骤3中得到的输出中获取一系列概率值,对于每个概率,通过阈值的设置来判断数据是否异常然后计算一系列概率的精确度、召回率和f1分数。精度可使用以下公式计算,
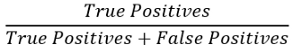
召回率的计算公式如下:
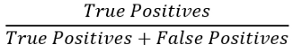
在这里,True positives(真正例)是指是异常的且算法检测到也是异常的样本。False Positives(假正例)是指不是异常的但算法检测到是异常的样本。False Negative(假反例)是指不是异常的且算法检测到也不是异常的样本。从上面的公式你可以看出,更高的精确度和更高的召回率说明算法性能更好,因为这意味着我们有更多的真正的正例,但同时,假正例和假反例也起着至关重要的作用,这需要一个平衡点,根据你的行业,你需要决定哪一个对你来说是可以忍受的。一个好办法是取平均数。计算平均值有一个独特的公式,这就是f1分数,f1得分公式为:
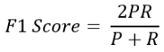
这里,P和R分别表示精确性和召回率。如果你对该公式感兴趣的话,可以查看:https://towardsdatascience.com/a-complete-understanding-of-precision-recall-and-f-score-concepts-23dc44defef6
根据f1分数,你需要选择你的阈值概率。异常检测算法我们将使用Andrew Ng的机器学习课程的数据集,它具有两个训练特征。我没有在本文中使用真实的数据集,因为这个数据集非常适合学习,它只有两个特征。在任何真实的数据集中,都不可能只有两个特征。有两个特性的好处是可以可视化数据,这对学习者非常有用。
请从该链接下载数据集:https://github.com/rashida048/Machine-Learning-With-Python/blob/master/ex8data1.xlsx首先,导入必要的包import pandas as pd ,import numpy as np,导入数据集。这是一个excel数据集。在这里,训练数据和交叉验证数据存储在单独的表中。df = pd.read_excel('ex8data1.xlsx', sheet_name='X', header=None),df.head()
让我们将第0列与第1列进行比较。plt.figure(),plt.scatter(df[0], df[1]),plt.show()

你可能通过看这张图知道哪些数据是异常的。检查此数据集中有多少个训练示例:m = len(df)





